
In God we trust. All others must bring data

«Big Data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it».
— Dan Ariely
В 1880 году Бюро по переписи населения США столкнулось с неожиданной проблемой. По их подсчетам, анализ переписи 80-го года продолжался бы около 10 лет — как раз до следующей переписи, запланированной в 1890 году. Решение вскоре было найдено молодым ученым, Германом Холлеритом, разработавшем электрическую табулирующую систему, которая увековечило его имя и позволило завершить анализ данных за 3 месяца.
Компания, основанная Холлеритом, в последствии станет одной из составляющих молодой IBM.
Это, естественно, не первый пример столкновения с проблемами больших данных, когда информации настолько много, что ее просто невозможно адекватно обработать: первые счеты появляются в Вавилоне (2400 лет до н. э.), и примерно в это же время возникают первые библиотеки — информацию нужно где-то хранить.
Достояние Александрийской библиотеки оценивается в сотни тысяч свитков — исполинская база данных для того времени, история которой закончилась плачевно. Рукописи горят. С изобретением книгопечатания человечество достигает плотности информации примерно 500 символов на кубический дюйм — в 500 раз больше, чем у шумерских глиняных табличек.
В 1957 году первый жесткий диск от IBM стал настоящим прорывом: будучи размером с два небольших холодильника, он позволял хранить целых 3,75 мегабайта информации.
Объем всех жестких дисков, CD, DVD в 2007 году оценивался примерно в 62 экзабита (= 1018 байтов или миллиард гигабайтов). В 2015 Seagate презентовала жесткий диск с плотностью информации 1,34 терабит/кв. дюйм, что в 600 000 000 раз больше плотности памяти первого жесткого диска.
Данными может быть все: биржевые индексы, научные публикации, запись показаний градусника на улице, СМС-сообщения, лайки, которые вы ставите, чек на валерианку, проданную вашей бабушке в ближайшей аптеке, и количество денег за нее заплаченных. Персональные гаджеты с доступом в интернет производят ежедневно огромное количество данных: достаточно заглянуть в приложение «Здоровье» от Apple. Выгрузив в один прекрасный день данные оттуда, я обнаружил 84 572 записи частоты пульса, около 15 000 пройденных дистанций, 400 записей о количестве пройденных этажей и 10 000 порций сожженных калорий. Возьмите такую информацию от тысячи пациентов — и вам будет некуда ее сохранить.
Исторический рост скорости получения и объема информации получил название «информационного взрыва». Лавинообразно растет не только обьем данных, но и скорость их обработки — это так называемый «закон Мура» (Moore's law), названный в честь Гордона Мура, одного из основателей Intel, заметившего, что каждые два года количество транзисторов в новых процессорах удваивается.
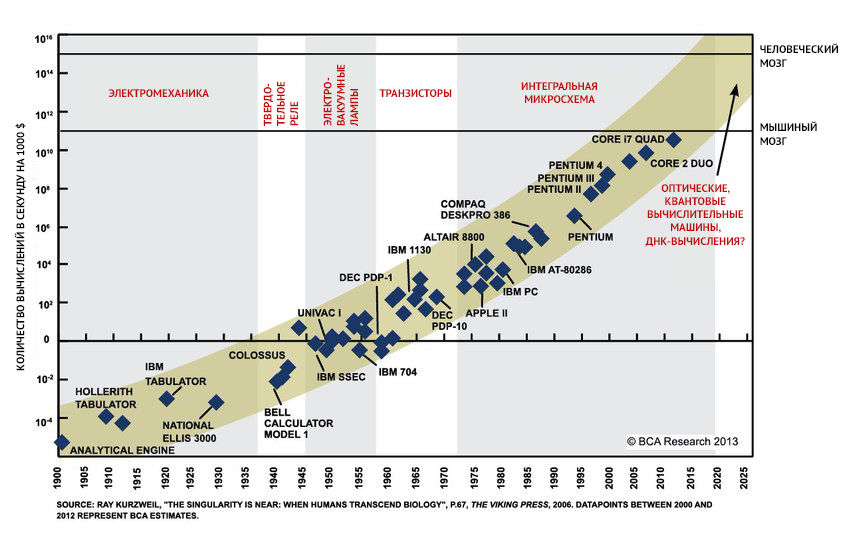
Большие данные (анг. Big Data) — это и констатация факта, и совокупность методов решения проблемы: данные недостаточно где-то хранить, их нужно передавать и анализировать. Традиционно в больших данных выделяют три свойства: volume, velocity, variety — объем информации, скорость ее накопления и обработки, разнообразие (анализировать можно любую информацию, достаточно перевести ее в приемлемый формат). Для анализа больших данных существует гигантское количество методов: от классического статистического анализа до разнообразных методов машинного обучения.
Наличие астрономического объема информации и острой необходимости что-то с ней делать привело к появлению data science — науки о том, как данные получать, понимать и помогать понять другим.
Первыми с Big Data в естественной науке столкнулись физики и астрономы: большой адронный коллайдер, например, производит 25 ГБ данных в секунду (~86 ТБ данных в день), а Large Synoptic Survey Telescope способен записать 15 ТБ информации за ночь. Такой объем данных просто невозможно сохранить для последующего анализа. Выходом может быть обработка в реальном времени, которая очень сложна и требует огромной вычислительной мощности: большая часть информации обрабатывается in situ, и грубые данные не сохраняются вообще.
В отличие от физики, биомедицина использует иной подход: необходимо записать информацию о каждом белке, каждом нуклеотиде, каждой РНК, считанной с определенного участка ДНК. Часть информации невозможно тут же отбрасывать как «ненужную» — она может пригодиться потом.
Наука о геномах все еще находится на стадии описания. Нужно прочесть как можно больше последовательностей, от митохондрий человека до генома морского конька.
Количество данных в этой отрасли удваивается каждые 7 месяцев. Наравне с ней стремительно развиваются и другие «омики»: эпигеномика, протеомика, транскриптомика, метаболомика…
Эти области питают десятки различных баз данных: Protein Data Bank, например, содержит данные о структуре 118 000 белков, пополняясь десятками тысяч новых структур ежегодно. Sequence Read Archive хранит 250 000 человеческих геномов, 32 000 — бактериальных и около 5000 растительных/животных (и прочих эукариотических, если угодно).
Секвенируют больше, секвенируют дешевле: если в 2001 году стоимость прочтения генома составляла ~100 000 000 $, то в 2015 году она пробила отметку 1000 $. Трудно найти другой пример технологии, подешевевшей в сто тысяч раз за 15 лет.
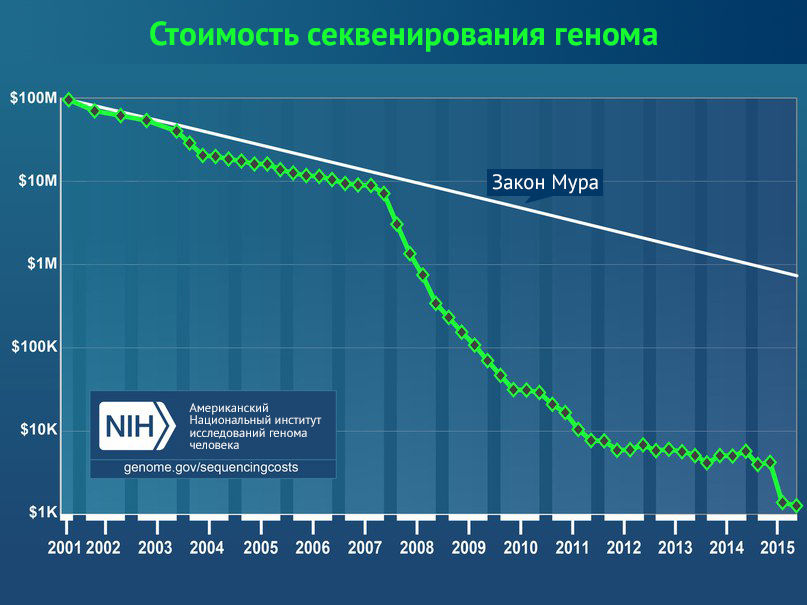
Еще до недавнего времени компания «23andMe» в США предлагала определить последовательность десятков генов всего за 99 $, прочитав к 2017 году последовательности двух миллионов человек.
Однако данные недостаточно получить — из них нужно извлечь информацию. И это, пожалуй, самое интересное. Меткое английское название добычи данных — data mining — хорошо описывает ситуацию: аналитики похожи на шахтеров с кирками, достающих из гор грубой информации крупицы новых знаний. В конце концов, геномы после секвенирования — это просто набор чередующихся букв. Самое интересное впереди: необходимо найти нуклеотиды, которые у разных людей отличаются — однонуклеотидные полиморфизмы — и, возможно, связать их с признаками заболеваний.
Этот подход получил название полногеномного поиска ассоциаций (Genome Wide Association Studies, GWAS). Анализ геномов занимает огромное количество времени и требует больших мощностей. Если еще 20 лет назад в GWAS использовались геномы десятка пациентов, то сейчас это тысячи и сотни тысяч. Но даже если отличие найдено, это ничего не говорит о наличии болезни: отличающийся нуклеотид может не прямо влиять на первичную структуру белка, а, например, изменять уровень экспрессии белка в конкретной ткани, более того — в отдельных клетках в определенное время. Наивные примеры серповидноклеточной анемии и альбинизма хороши лишь для школьных учебников — с таким подходом не понять патогенез болезни Паркинсона или шизофрении. Бесполезность концепции «один белок — одна болезнь» и взаимодействие всех компонентов клетки довольно метко описывает омнигенетическая модель: все связано со всем.
Человечество еще невероятно далеко от понимания того, как работает геном: как на него влияют эпигенетическая изменчивость, конформация ДНК в трехмерном пространстве, спектр РНК в ядре и белков в цитоплазме и прочие факторы. 20 000 белков — лишь вершина геномного айсберга.
«Если бы в магазине продавали машинное обучение быстрого приготовления, на коробке было бы написано: «Просто добавь данных»
Педро Доминигос, «Верховный алгоритм»
Что же делать с гигантскими массивами данных?
Выход из сложившейся ситуации есть — дать компьютерам самим анализировать. Этот подход давно известен под разными названиями «машинного обучения». Конечно, для анализа относительно простых данных никакой «искусственный интеллект» не нужен — достаточно природного, человеческого, вооруженного пакетами для R, Python или Excel, на худой конец. Но для анализа большого количества данных, в которых есть и нелинейные взаимосвязи, намного правильнее использовать машины.
Общая суть в том, чтобы алгоритм сам искал взаимосвязи в данных, делал заключения, строил модели и на их основании мог делать прогнозы. Машинное обучение широко и очень успешно используется в бизнесе для прогнозирования поведения покупателей, цен на нефть и состояния биржи. Торговые гиганты, такие как Amazon и, например, Airbnb, используют сложные алгоритмы для удовлетворения потребностей покупателей. Алгоритмы могут находить в массивах данных такие взаимосвязи, которые не под силу заметить человеку: широко цитируется забавный пример с пивом и подгузниками. Американская торговая сеть Wal-Mart заметила, что пиво продается лучше, если разместить его рядом с подгузниками. Вывод совершенно не очевидный, но объяснить такую находку можно следующим: мужчины, посланные женами в супермаркет за подгузниками, покупают себе пиво в качестве вознаграждения. И хотя эта история является выдумкой, она хорошо иллюстрирует то, чем занимаются специалисты по машинному обучению — поиск закономерностей, порой и тех, которые человеку найти не под силу.
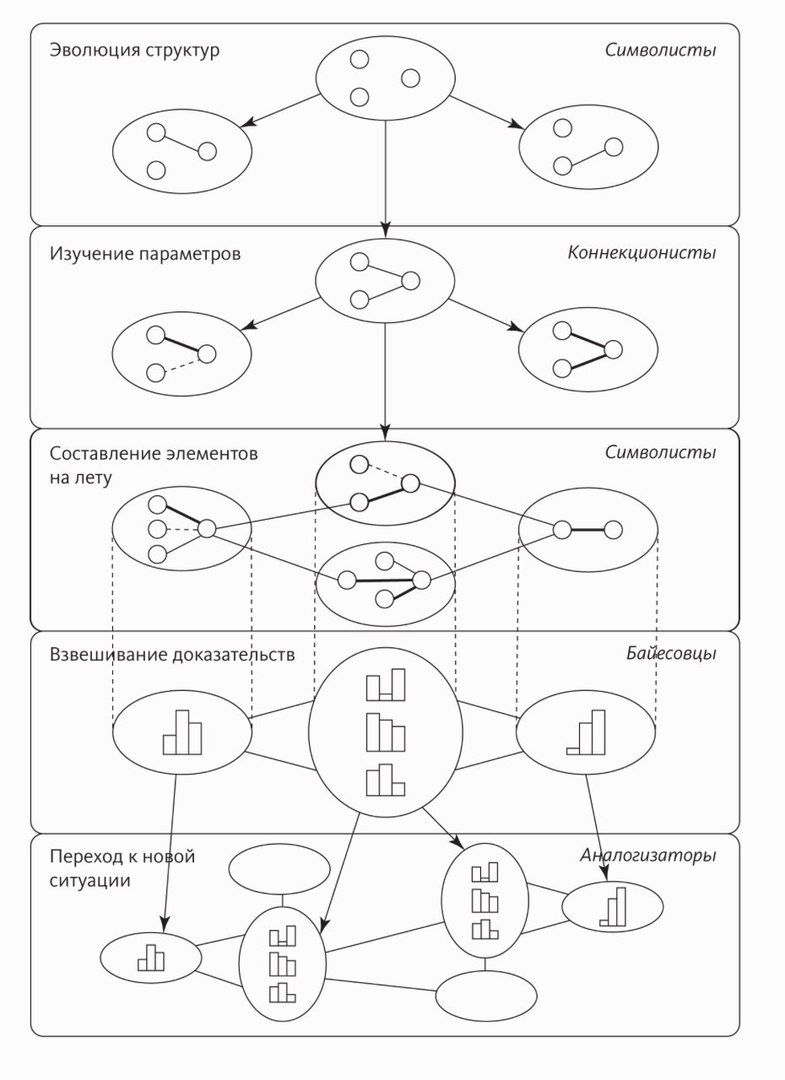
Для обучения машин существует множество подходов: тут и нейронные сети, и теорема преподобного Байеса, и даже искусственная эволюция программ. Суть в том, что мы не знаем, какие закономерности найдет алгоритм в данных, нам это не так интересно. Важно, чтобы он мог на основании этих моделей выполнять то, что от него требуется. Дайте алгоритму достаточно большую выборку данных (например, гистологические препараты с отметками: «это карцинома», «это аденома»), и он способен научиться их сортировать. Естественно, алгоритм может просто «зазубрить» изображения — так называемое «переобучение». Чтобы этого избежать, эффективность программы проверяют не на обучающей выборке, а на новой — тестовой. Довольно часто программы, великолепно справлявшиеся с обучающей выборкой, терпят настоящее фиаско в «дикой природе» новых данных.
В медицине машинное обучение используется сравнительно недавно, но уже достигло значительных успехов.
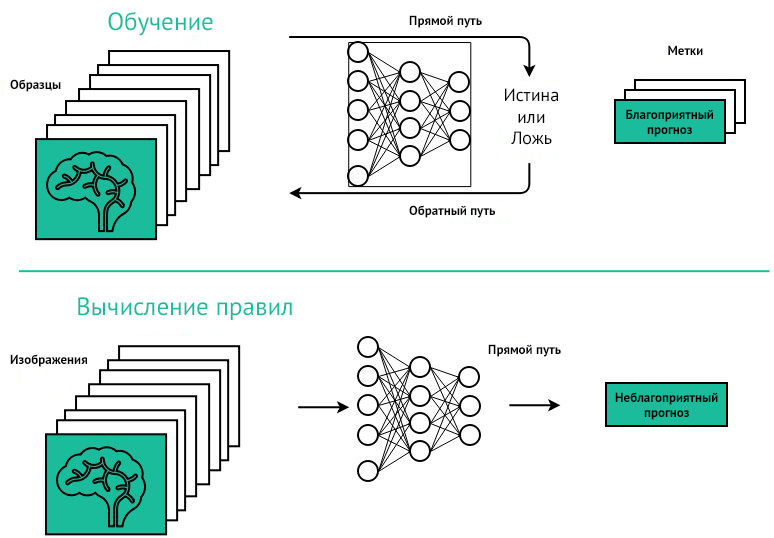
1) в первой фазе алгоритму предоставляется обучающая выборка (training set) из изображений с вручную отмеченными патологиями; в этой фазе алгоритм учится находить взаимосвязь между изображением и патологией;
2) во второй фазе эффективность программы проверяется на тестовой выборке.
В июне 2016 в Nature была опубликована статья о сверхточной нейронной сети, которая научилась отличать меланому на фотографии от доброкачественных новообразований кожи и делала это не хуже более двадцати сертифицированных дерматологов. Перспективы этой программы огромны, если ее удастся упаковать в удобочитаемый интерфейс смартфона.
Примерно тот же подход уже использовали для диагностики рака простаты. Еще более поразительный пример — алгоритм IBM Watson, способный анализировать огромные массивы данных о пациентах, способах лечения заболеваний, клинических испытаниях, журнальных статьях и в результате выдавать рекомендации по лечению конкретного пациента. Трудно сомневаться в том, что опыт одного врача не сравнится со всеми публично доступными медицинскими данными в мире, и поэтому проект от IBM способен изменить клиническую медицину в недалеком будущем.
Источники:
- Domingos P. The master algorithm: How the quest for the ultimate learning machine will remake our world. – Basic Books, 2015.
- Stephens Z. D. et al. Big data: astronomical or genomical? //PLoS biology. – 2015. – Т. 13. – №. 7. – С. e1002195.
- Eisenstein M. The power of petabytes //Nature. – 2015. – Т. 527. – №. 7576. – С. S2.
- Hilbert M., López P. The world’s technological capacity to store, communicate, and compute information //science. – 2011. – Т. 332. – №. 6025. – С. 60-65.
- “Boyle E. A., Li Y. I., Pritchard J. K. An expanded view of complex traits: from polygenic to omnigenic //Cell. – 2017. – Т. 169. – №. 7. – С. 1177-1186.
- Irizarry, R., Love, M. (2017). Data Analysis for the Life Sciences with R. New York: Chapman and Hall/CRC.
